Debezium, Kafka and Transactional Outbox — The challenges
What I have learnt from running Debezium Connectors with Kafka cluster at scales
Why do we need transactional outbox?
In the realm of microservices, often, application will have its own datastore. It can be a MySQL or PostgreSQL database that the application can persist data into. At the same time, the same application will want to send an event/notification to other downstream applications via a message queue. This dual write solution may cause potential inconsistencies. This could happen when either of the writes ( to message queue or to local database ) experiences failure while the other is sent successfully
Hence, we will have this question.
How to reliably update the database and send messages/ events?
What is Transactional Outbox Pattern then?
This pattern consists of an OUTBOX table that service/application will insert message/ event into. After that, we have a message relay (Debezium Connector in this case) that listens to the table changes (via binlog file) and publish the data into message broker ( Kafka cluster )
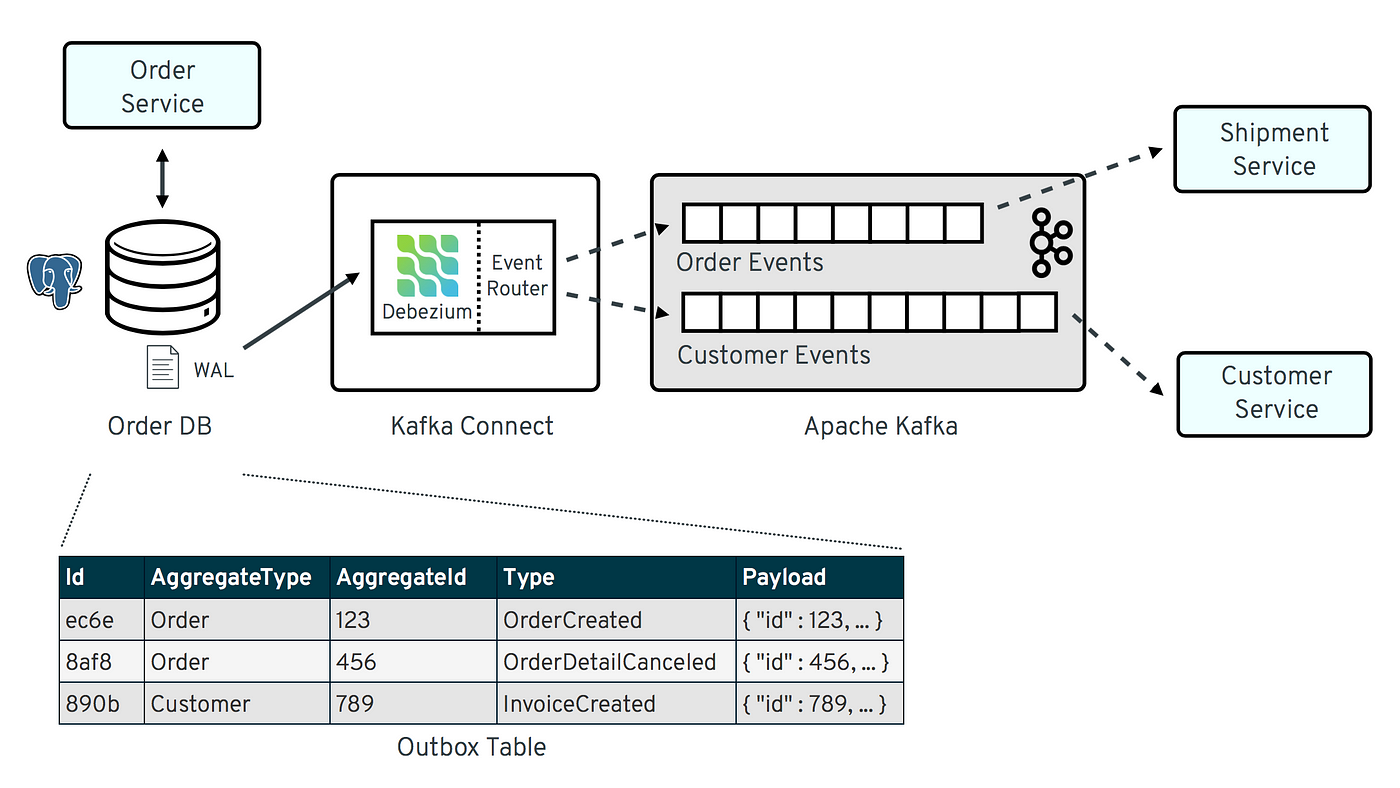
Subsequently, separate downstream applications will consume from those event in Kafka topics as a form of events
What are the benefits of Transational Outbox Pattern?
- Upstream application only needs to write once to the database
- Messages to downstream applications are guaranteed to be sent if and only if the database transations successfully commits
- The message are sent to Kafka broker in the order they were sent by the application
Now we have some context about Transactional Outbox Pattern, lets discuss its challenges and how I overcome it when running in production environment
The Setting
- A Kafka Connect cluster will be spun up to run several Debezium Kafka Connectors. Each cluster will consists of minimum 3 worker nodes. In this article, each worker node corresponds to a Kubernetes pods
- Each Debezium Connector consists of a single Connector task. This task will resides in one of the worker pod. There can be multiple debezium connectors running in a single worker pod
Challenge 1: Connector Status is RUNNING but Task Status is FAILED
{
"name": "test",
"connector": {
"state": "RUNNING",
"worker_id": "localhost:8083"
},
"tasks": [
{
"state": "FAILED",
"id": 0,
"trace": "ERROR MESSAGE",
"worker_id": "localhost:8083"
}
]
}Actually, this is a “common” problem for all other types of Kafka Connector, not just Debezium. What we can see from the picture is that
- There is only 1 task running for this Debezium connector
- This task status is FAILED while the connector status is still RUNNING. Technically speaking, the connector is down
Solution:
- Usually, in this case, the first thing we try ( and so often it works wonderfully) is to restart the connector task via Connector API
- Set proper alerting rules at the task level, not connector level
- If we want to automate this restart operation even more, we can create a cron-job that restart all failed task after a fixed period of time (15 mins might be a good start). rmoff has outlined this in detailed in this blog
Challenge 2: Source Database cutover
How does Kafka Connect Debezium tracks its offset? So that in case of failure, it can continue to read from the point where it left off previously? Internally, Kafka Connect tracks the offset in a metadata kafka topic that is indicated in offset.storage.topic config. Please take note that Connector does not store offset in __consumer_offsets topic like the normal consumer group
Often, Debezium connector connects to source database host via a DNS record. I.In many of the case, there will be updates to the database instance, that sits behind this DNS record (version update, hot fix etc) .

As seen in the picture above, when the Green( Non Production ) Database cluster is switched over, the binlog file name and position is not the same as the old one that we stored in offset.storage.topic kafka topic .If we don’t do anything to our connector, it is guaranteed to fail.
Solution:
- During the switch over ( step 4 of the diagram ) we need to “tell” the connector which new binlog position, binlog file and server name it will continue to read from. We should be able to get it from our Database Ops team .
- Pause the connector
- Manually insert this offset position, binlog file name and server name into the offset topic from
offset.storage.topic. The detailed step can be found from Debezium official doc here - Restart the connector
Challenge 3: Huge DML operation , CPU throttled and noisy neighbor
As Debezium records changes from the binlog file at the row level. Each row affected will be counted as 1 event/ kafka message. Hence, for huge DML operation that affect millions of row ( yes I have worked with DML changes resulting in 50 Millions rows), there will be a sudden influx of messages from our Debezium
With a sudden huge number of messages are sent into our Kafka topic, some part of our system can become the bottle neck:
- If we don’t provision enough resources ( CPU cores ) to our worker node pod, there will be CPU throttled, leading to very few messages produced into Kafka
- If our Kafka topic does not support that high level of throughput, it can limit how many messages per second can be consumed/produced to kafka
We will run a risk of (a) failure to produce that much messages to kafka before the binlog retention. This will cause data loss (b) failure to consume that much message from Kafka by downstream application before Kafka topic retention period (c) affecting all of the Debezium Connector running in that same pod because of this noisy neighbor

Solution: some of these / a combinations of these solutions have proven to work for me
- Clear communication of such events : Prevention is better than cure. If we can prepare for this event, instead of reactively fighting the fire, it would be much better. This is even more crucial when each component is own by different teams ( database by Database Ops team, Debezium and Kafka by Platform team, downstream applications by respective service team etc)
- Increase the retention period binlog file / kafka topic. This will allow Debezium/ Kafka Consumer to be able to produce/ consume all of the event
- Set appropriate number of partition for our Kafka topic. The number of partition per topic determine the level of parallelism for our topic. It can greatly increase the read/write throughput of our Debezium/ downstream application. Note : once you increase the partition number of a topic, you won’t be able to decrease it back
- Temprorarily privision for more resource: For Kafka Connect worker node, you can increase the number of CPU core or set a much higher
cpu_limitthan the currentcpu_request. For application downstream, if possible, we can increase the number of host to match the number of partition of the topic ( number of host > number of partition does not work as it leads to idle consumer) - Set proper monitoring: we can set monitoring for the following (a) lag between debezium and host database (b) consumer lag (c) Abnormal changes in the incoming message ( week over week difference)
Note: There are some discussion from Debezium community about the performance of Debezium. I will leave it here for you to read more on
Challenge 4: Reading from non-existence binlog file
As the name suggests, the connector is trying to read from the binlog position which has been flushed by the database and no longer exists. Unfortunately, from my experience, there is not much we can do but accept the fact that we might have some missing data
Solution:
- Increase the retention period of the source data base.This is more like a preventive solution
Challenge 5: At-least-once delivery semantics
As we are in the realm of distributed system, failure is always expected. Things may be running fine most of the time, but what counts is in the unwanted event of failure. If Debezium crashes after it has sent message A to kafka but before it can commit the offset, things get complicated. After the restart, Debezium connector will look back at the offset, and fire event A again leading to duplicate data.

Solution:
When building downstream consumer application, we should have a deduplication mechanism in place. Once possible way is to used kafka message_id to as deduplication key
Summary
Transactional Outbox Pattern with Kafka and Debezium is a very useful and commonly used pattern. However, comes with it is another level of operational complexity that we have to account for
Hence, before we consider this approach, we need to asnwer a few questions:
- What do we stand to gain from this new implementation? What is the trade-off?
- Do we have an existing Kafka cluster and Kafka Connector cluster in use , or we are setting them up and managing them from scratch ?
